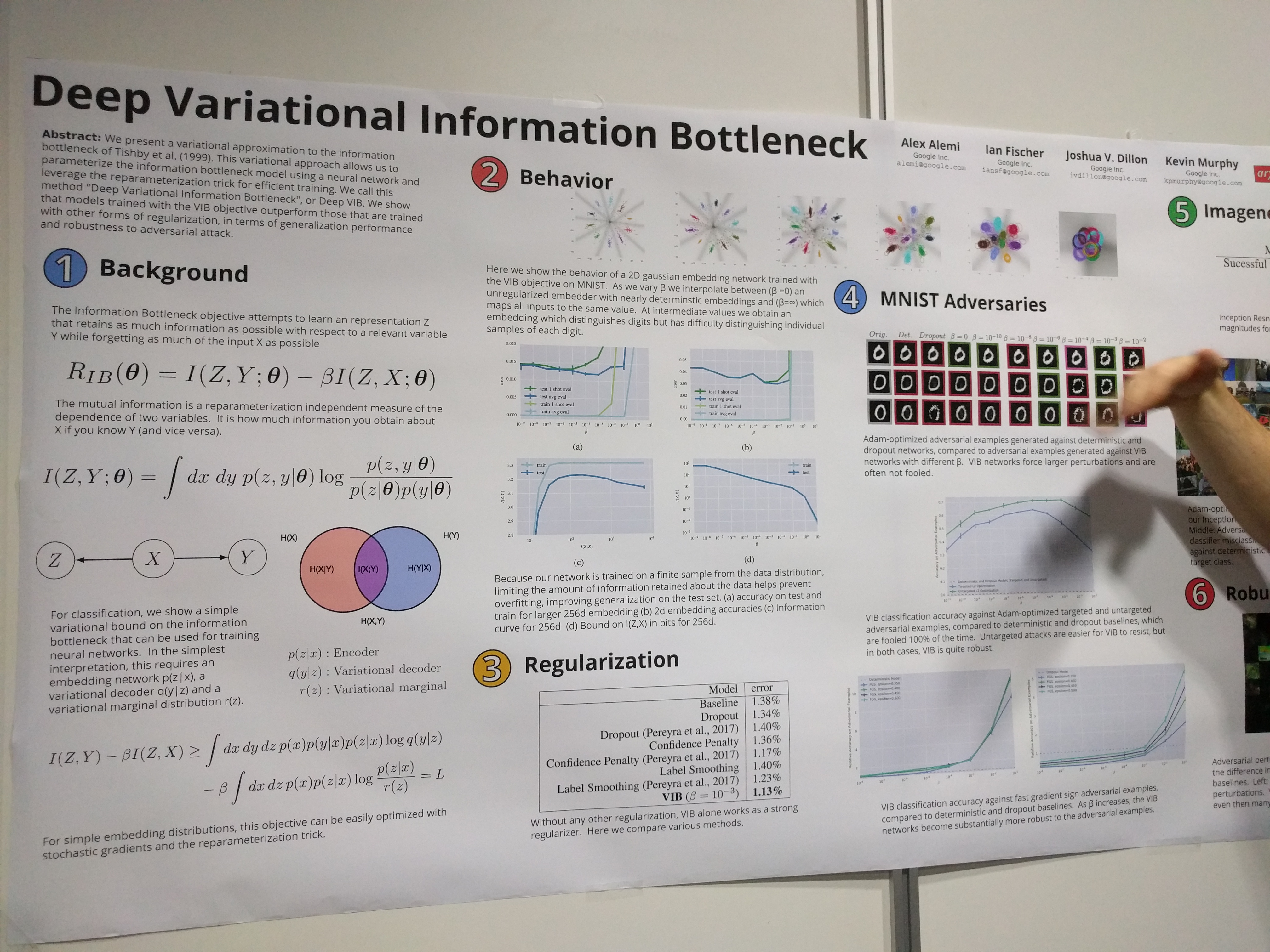
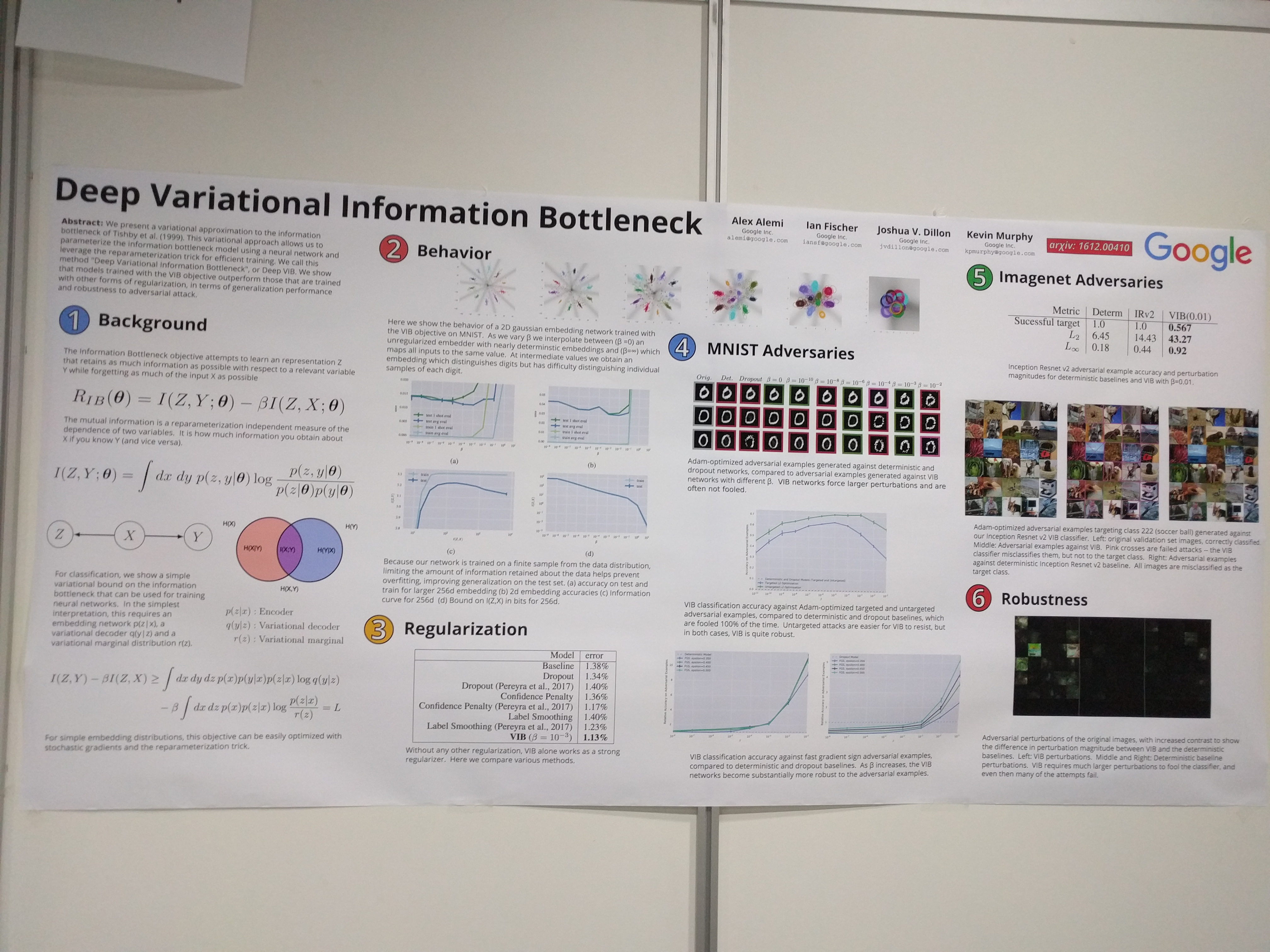
Cool way to implement the information bottleneck (Tishby et al 1999) in a variational network. Here it is not autoencoder, but actually a classifier, but with an explicit latent state. Now the latent state is optimized to maximize mutual information with the targets but minimize MI with the inputs. This forces it to extract only relevant information from the inputs (bottleneck). They show that this also helps against adversarial attacks.
Like VAE but particular for non-Markovian state transition models.
@Alex K.
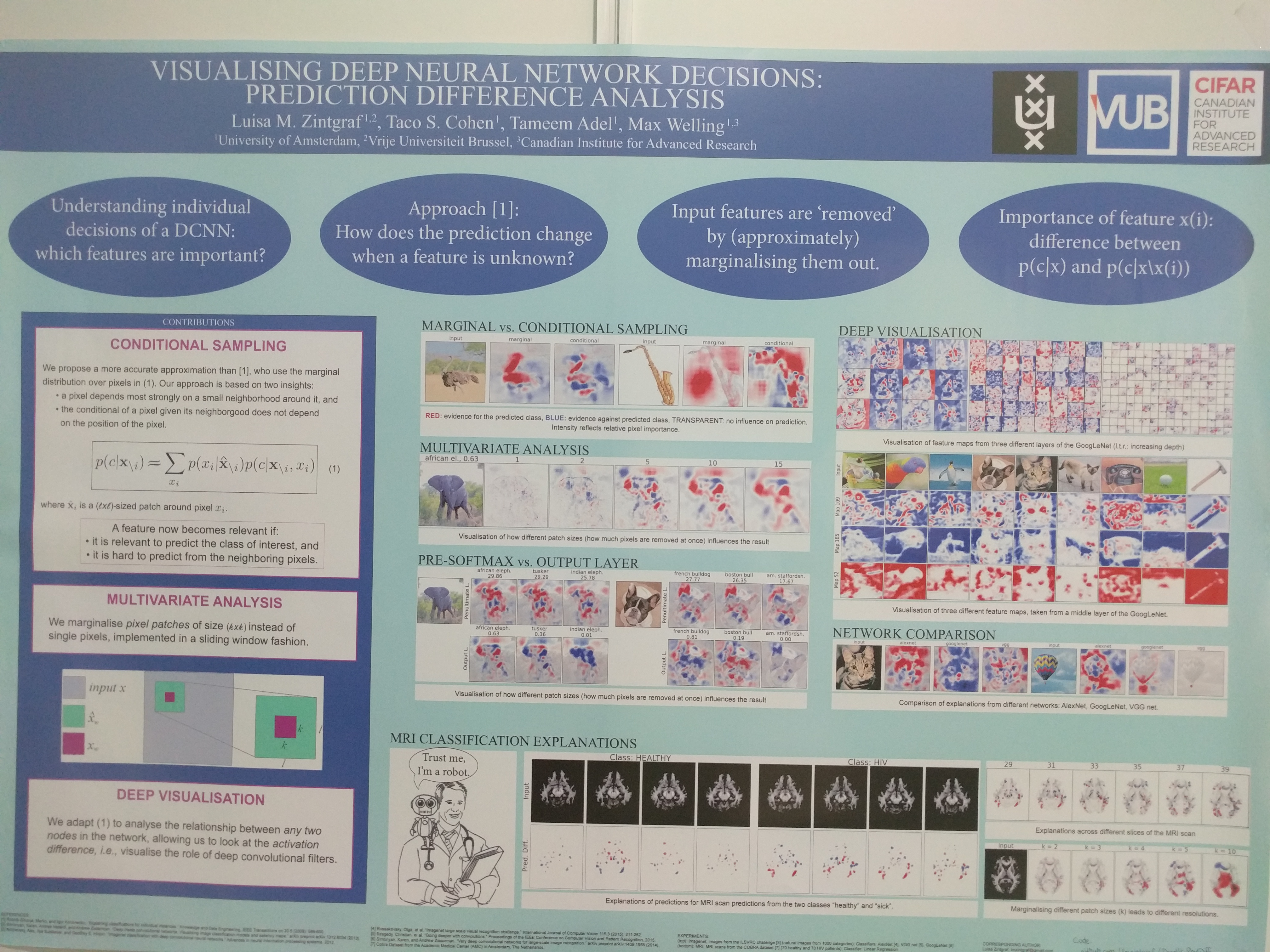
I found it interesting how they performed the conditional sampling to find out what is the effect of a single pixel. I just though that might also be somehow relevant for finding a segmentation in the weakly supervised case.
Use the generic task of prediction to structure the policy network. (playing Doom)
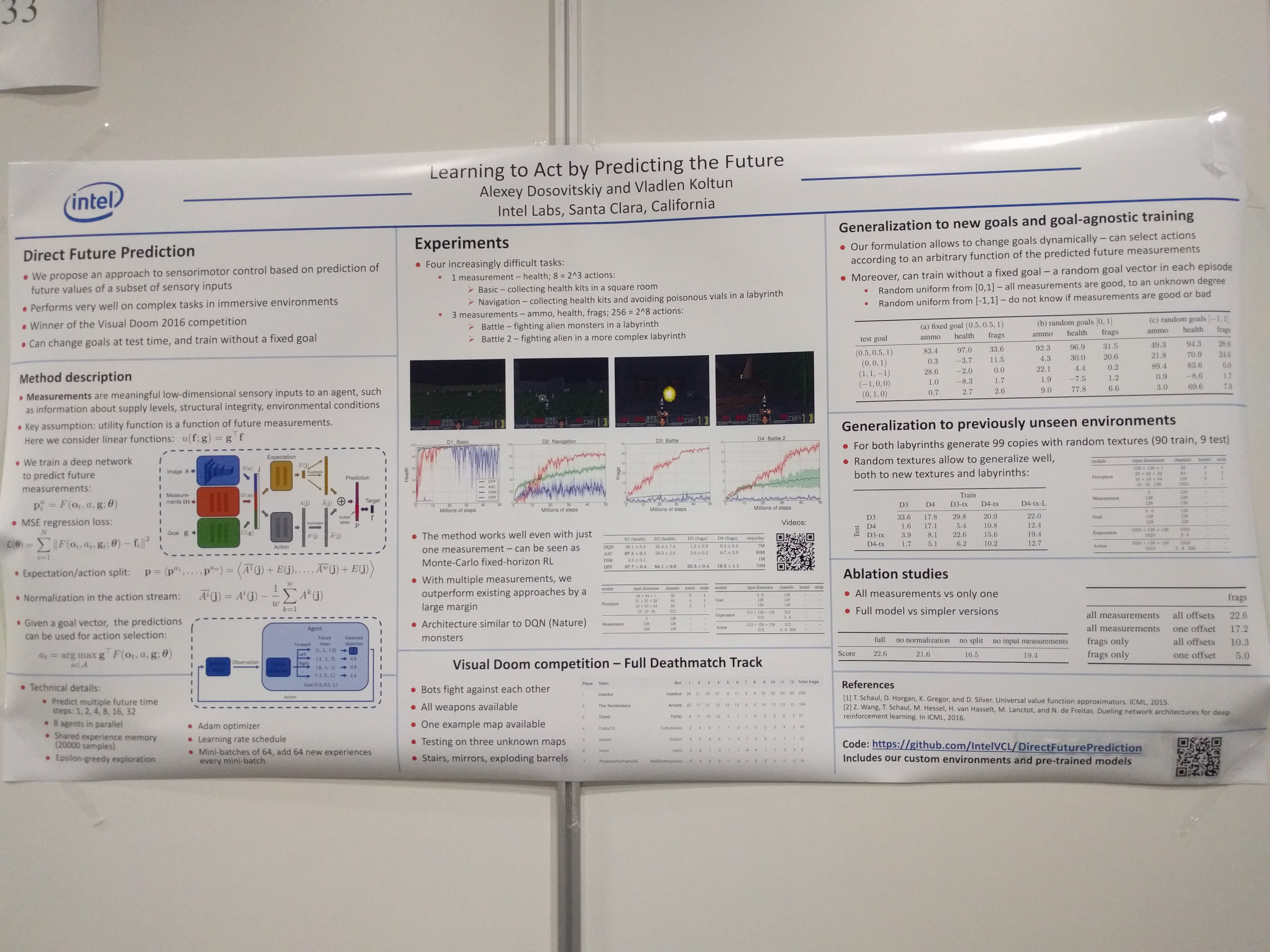
They use Bayesian Neural networks (A NN where the parameters are integrated out using MCMC) to model the system and then perform policy search on the model (if I understand correctly). They also show how a GP fails here. There is some other interesting thing that they use Alpha-divergence instead of KL-divergence for matching the approximated posterior.
Downside: sampling the posterior is computationally expensive (in contrast to GP)
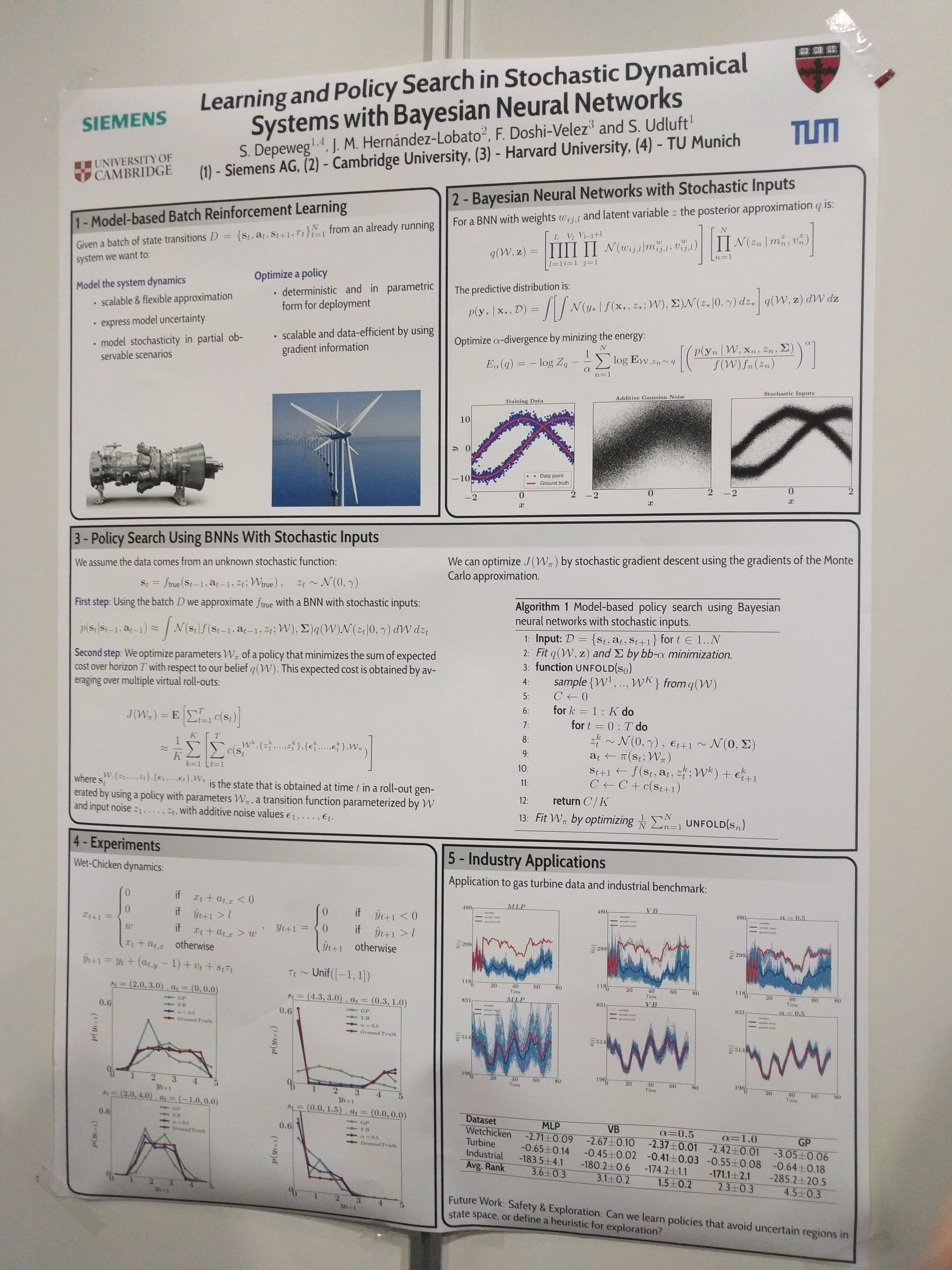
!!! Continue here!
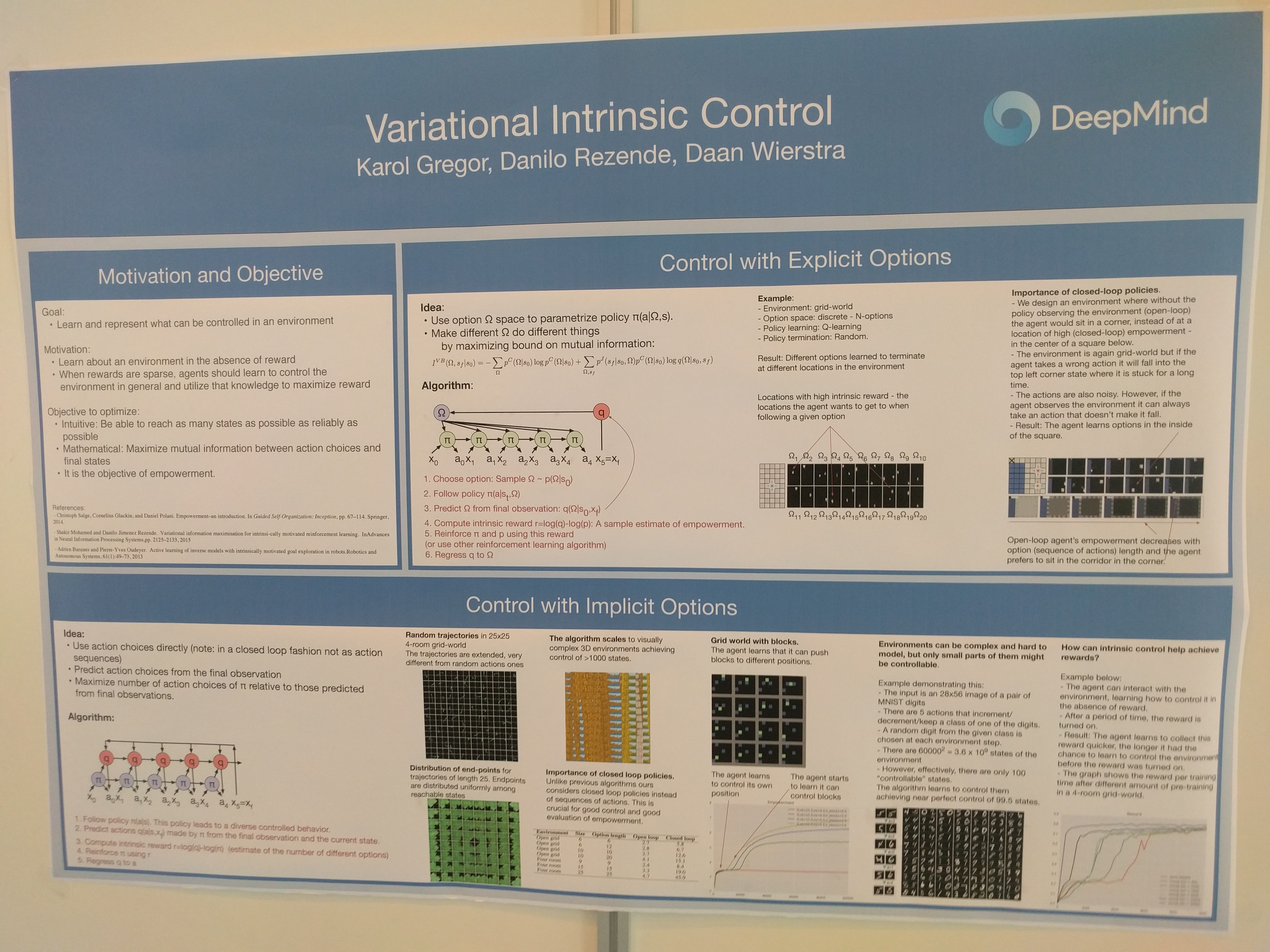
A way to implement Empowerment maximization in a RL framework with options.
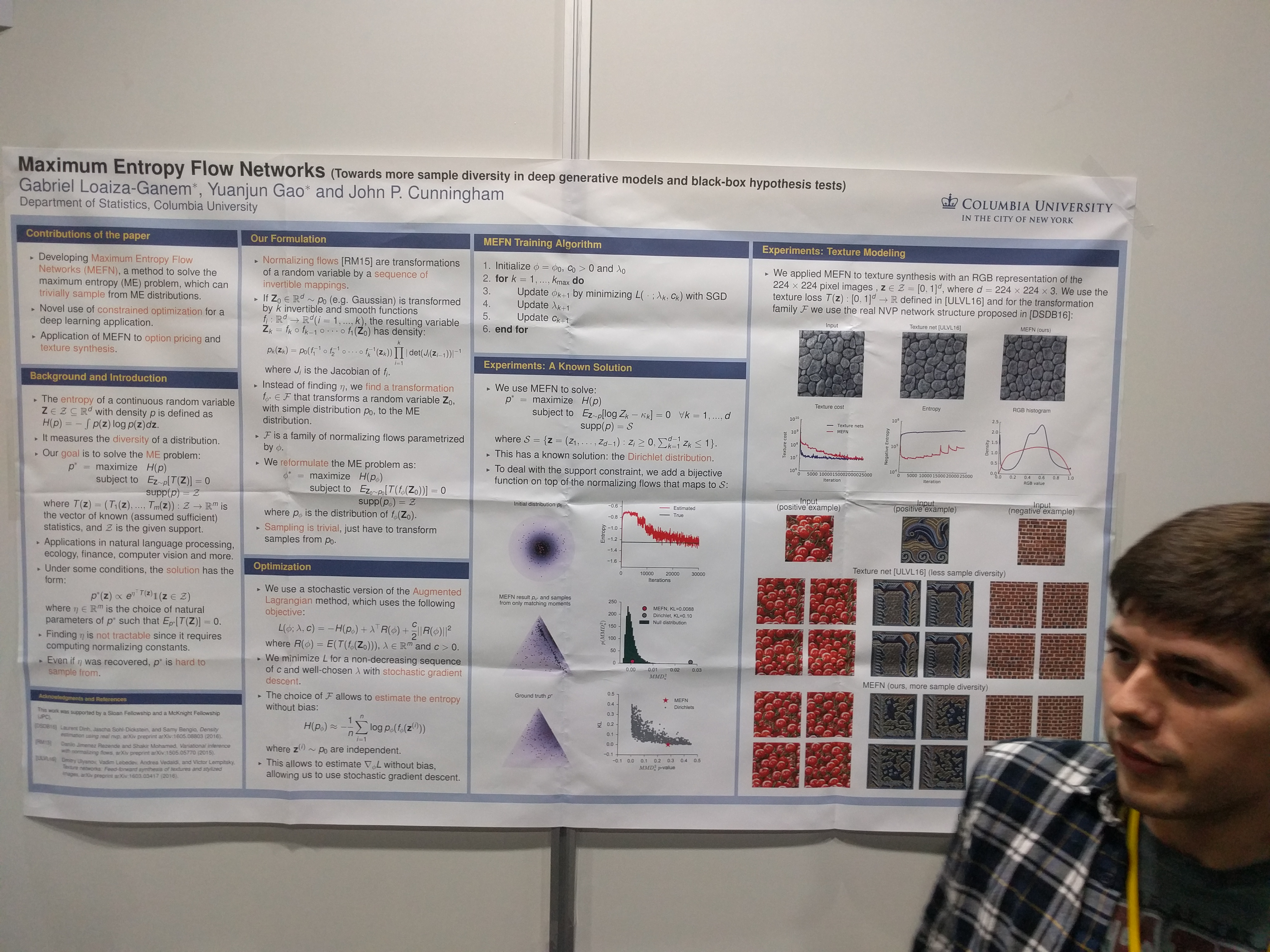
Method to find/model and sample from Max-Entropy distributions. (Distribution with maximum entropy under the constraint of matching the expected sufficient statistics of the given data.) They use it for instance for texture generation.
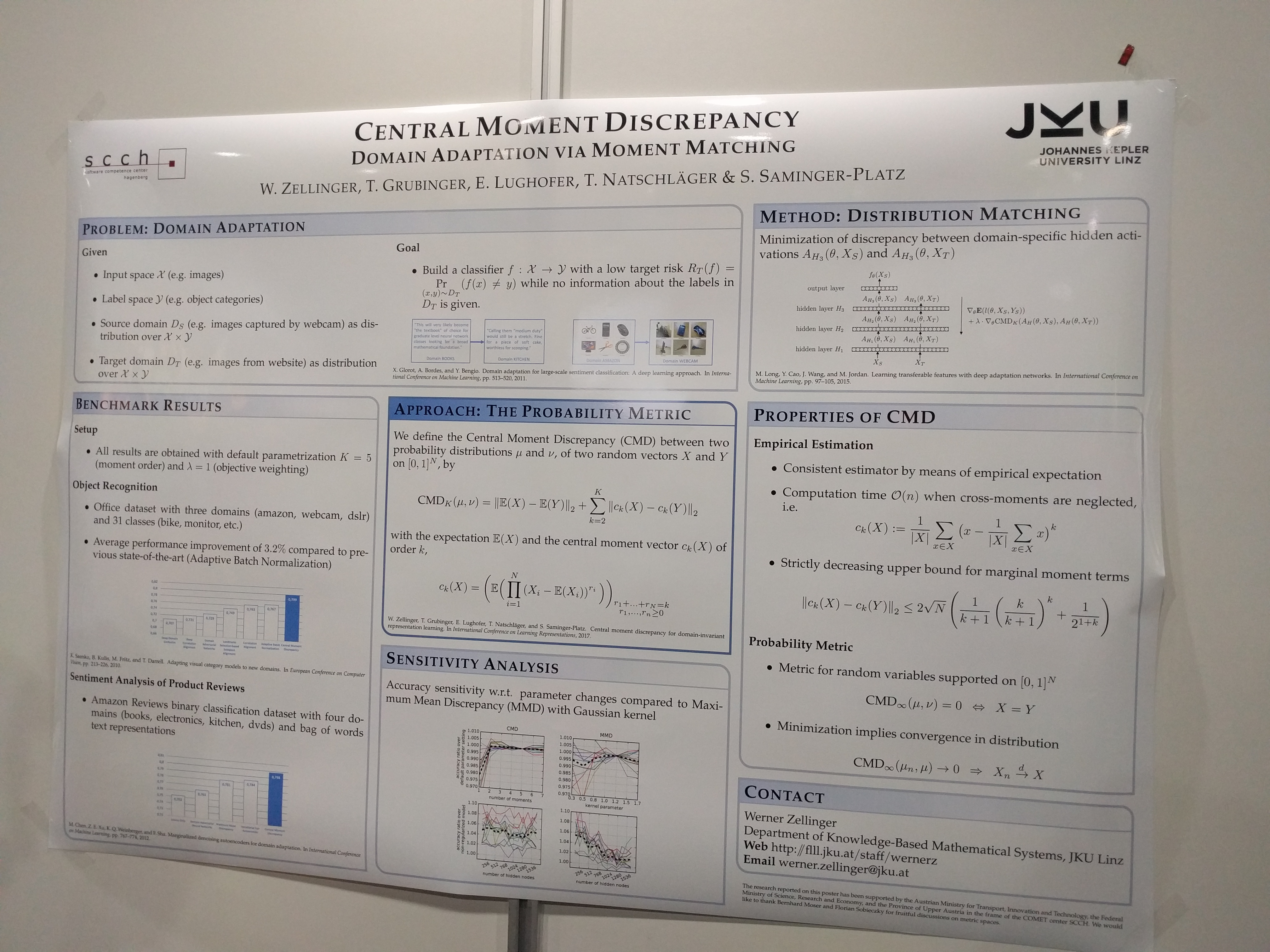
A demonstration that domain adaptation by matching central moments (up to order 5) is quite effective (and so simple :-)
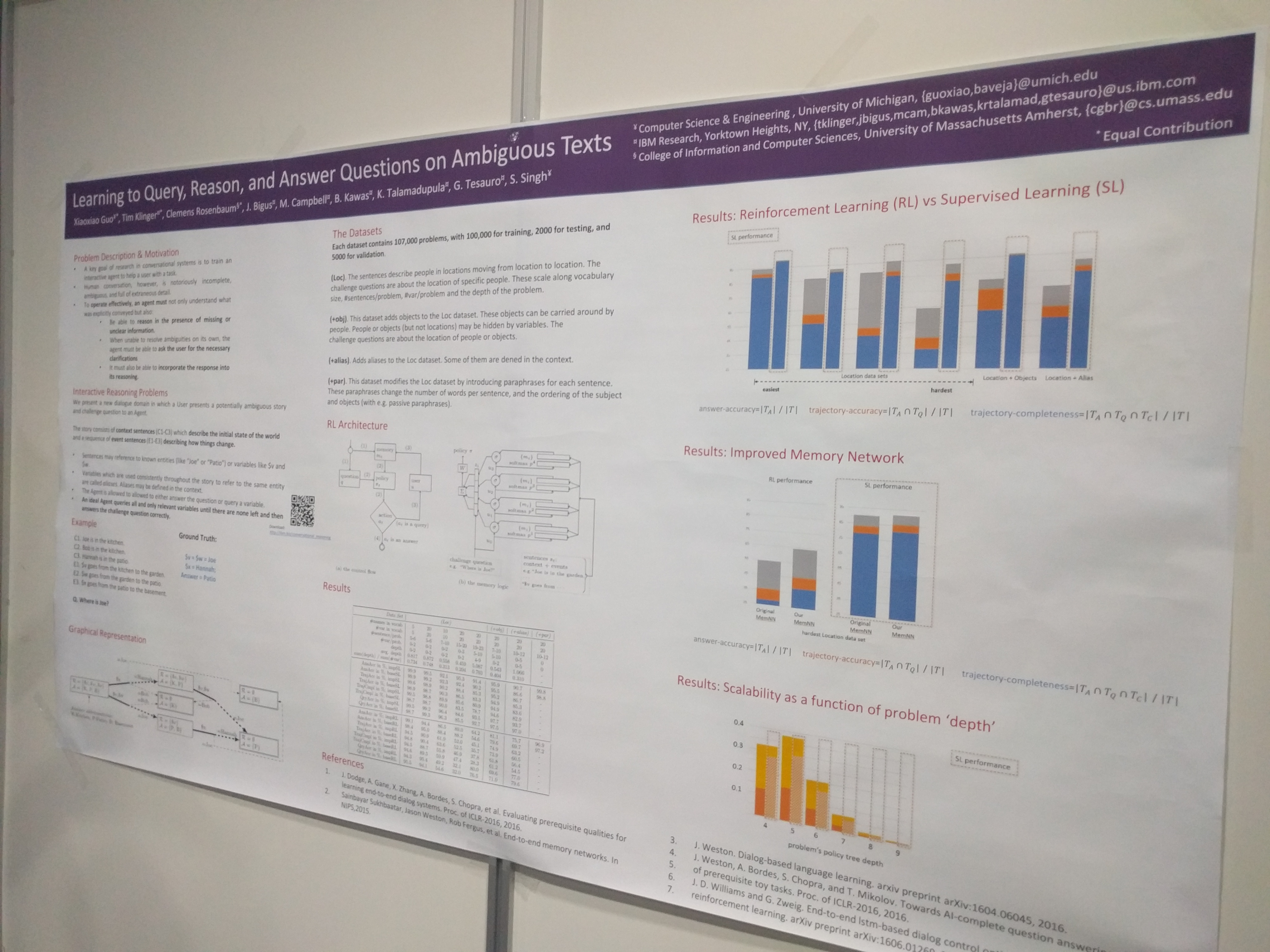
Like a memory network but it is designed to recusively modify the question (with the idea that the it learns how to ask simpler questions to figure out the actual answer). Very effective on bAbI for instance.

Like the bAbI task but with some facts having placeholders. Tried also reinforcement learning, but it was worst the supervised learning.
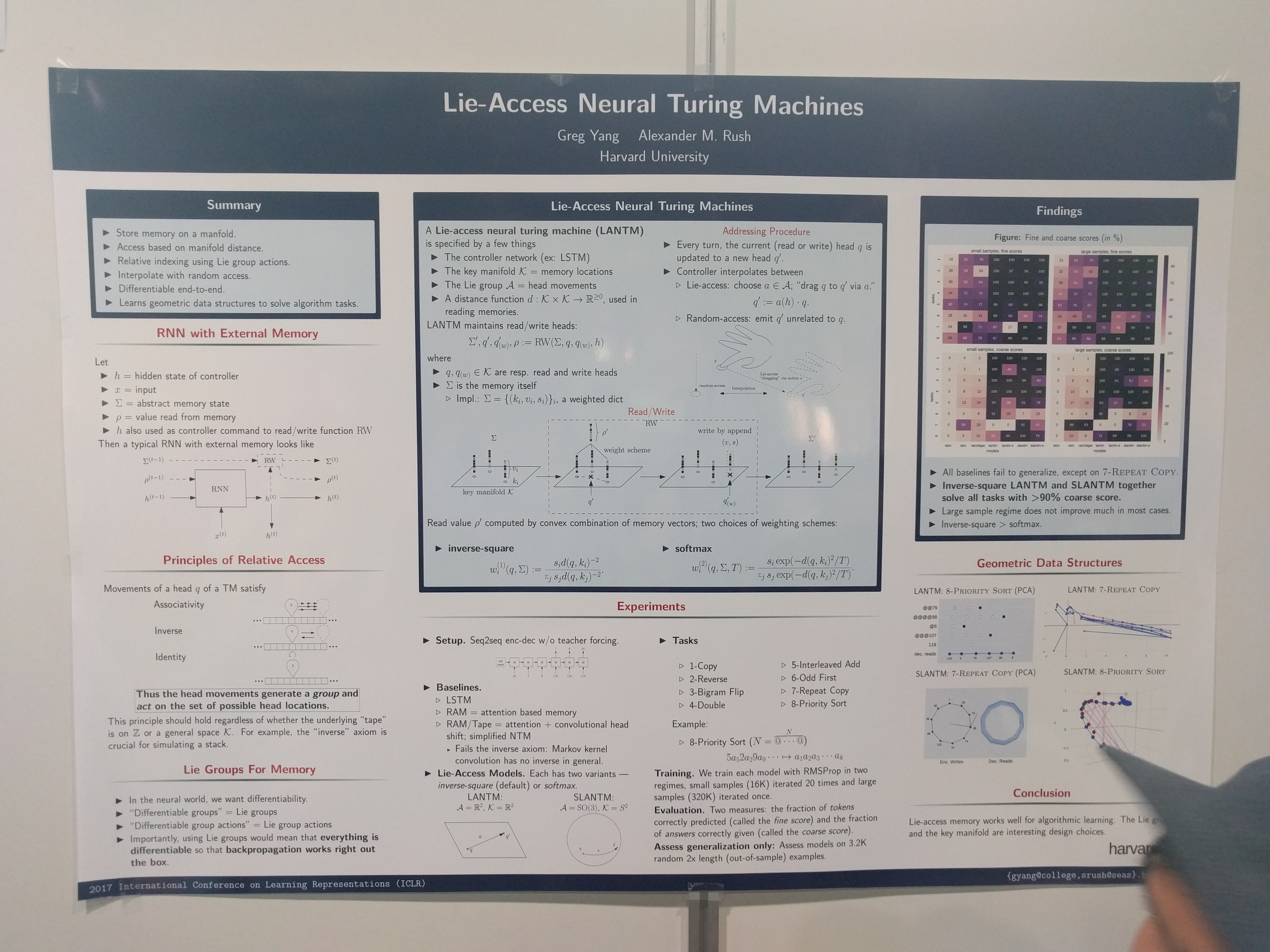
Fancy name for something rather simple, but the idea is nice: In the Neural Turing Machine (NTM) the memory is addressed by a 1D address. To make it differentiable the access is "smoothed" out by weighted access. Now by using a higher dimensional manifold for the address space (like a hypersphere or so) we can define operations on the addresses by a Lie-actions. Lie groups are groups with differentiable operations, such that backpropagation works nicely. So in practice we have a simple vector operations (like rotations in the sphere case). Writing to memory works by placing an element at the current location. Reading is done by weighted sum of the nearest memory entries given a certain address. Disadvantages:
needs a k-nearest neighbor search and
cannot delete/overwrite other than placing new entries next-by
Deep Learning with Sets and Point Clouds

It is essentially trivial: The permutation-equivariant layer can only do Ident and a uniform operation. Our DAC aggregation stuff might be more useful here?
Deep Learning with Dynamic Computation Graphs. Aka: Tensorflow fold library @Michal
Makes it possible to have much faster "dynamical" computation graphs